
23 May
2012
23 May
'12
4:35 p.m.
Dear all,
we just replaced the transcript quantification files in
analysis_data/quantification/transcript because we found that a script
which counted the number of mapped reads for the RPKM normalization
got confused by the whitespace characters inserted by the new
casava/Illumina pipeline into the read IDs. Therefore, the RPKM values
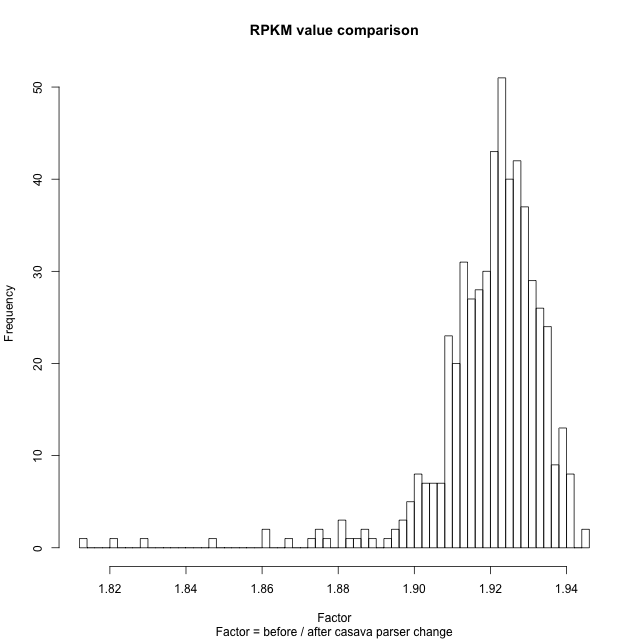
in the former files were off by ~ factor 2, the exact ratio old/new
varies expectedly few % around the median 1.92 (plot attached).
Hopefully this lapsus did not affect anybody's work--and please be
careful not to run into the same issue when emplyoing programs that
split columns by whitespaces on files with these read IDs; that was
really a great idea of Illumina.
Best,
micha
--
Dr. Michael Sammeth, GL Functional Bioinformatics
Phone: +34-934-020-580, http://www.cnag.eu
Centre Nacional d'Anàlisi Genòmica (CNAG), PCB
Baldiri Reixac 4-6, Room 02A8, 08028 Barcelona
{kind=link}